
Email bounce management is rarely discussed until something breaks.
Not because bounces are uncommon. But because most teams treat them as routine noise inside campaign reports.
The difference between average senders and mature sending organizations isn’t whether bounces happen. They always do.
The difference is whether bounce behavior is governed.
At scale, bounced emails aren’t a cleanup task. They are signals flowing through your delivery infrastructure. How your systems classify, suppress, retry, and monitor those signals determines long-term sender stability.
That’s why serious teams don’t just manage bounced emails. They implement bounce governance.
Why Managing Bounced Emails Is More Than Just Removing Invalid Addresses
You send 100,000 emails. The campaign looks clean. Segments are correct. The timing is right. Then the report comes in – 4% bounced.
What do you do next?
Most teams export the bounced list, remove the obvious hard failures, and move on. That’s handling. It solves the visible symptom. But it doesn’t answer the bigger question: why did the emails bounce occurred, how are they classified, and what prevents them from repeating?
This is where email bounce management becomes different from simply trying to manage bounced emails reactively. Mature teams treat bounces as delivery signals, not housekeeping tasks. A spike isn’t just a data problem – it’s a workflow trigger. It should initiate classification logic, retry rules, suppression updates, and monitoring alerts. That is infrastructure.
Basic handling says: delete hard bounces and continue sending.
Management says: detect → classify → route → suppress → monitor → audit.
There’s a structural difference.
If you’re unsure about the difference between soft and hard bounces, we’ve covered that in detail elsewhere. Here, what matters is that each type feeds into a broader bounce workflow. Soft failures may trigger retry policies with defined thresholds. Hard failures should immediately update suppression logic across your ESP and CRM. Temporary ISP-level rejections might require pacing adjustments rather than list edits.
Email bounce management is not a cleaning action. It’s deliverability governance.
Teams that operate at scale understand this. They build processes that assume bounces will happen – and define how systems respond automatically. When you do that, you’re no longer reacting to numbers in a dashboard. You’re controlling sending behavior as a managed system.
The Difference Between Bounce Handling and Bounce Management
Handling is reactive. A campaign finishes. You review reports. You remove failed addresses.
Management is lifecycle-driven.
In operational terms, handling happens at the campaign layer. Management lives at the infrastructure layer.
A proper system includes automated webhook ingestion from your ESP, real-time classification of SMTP response codes, predefined retry logic, and suppression rules synced across tools. There are documented SOPs defining how many retry attempts occur, when an address is permanently suppressed, and how bounce monitoring feeds into sender reputation reviews.
When teams say they “manage bounced emails,” what they often mean is they periodically clean them. True email bounce management means no human has to manually decide what to do after every send. The rules are already written.
That difference becomes critical once volume increases.
Why Basic List Cleaning Isn’t Enough at Scale
List cleaning is corrective. Governance is preventative.
Running verification tools periodically helps reduce invalid addresses entering your database. That’s useful. But cleaning alone does not stop recurring bounce cycles caused by poor acquisition sources, weak opt-in controls, or flawed retry logic.
At scale, repeated bounce patterns create subtle deliverability decay. You may not see an immediate collapse. Instead, inbox placement slowly shifts. ISPs adjust trust signals. Temporary rejections become more frequent. Throttling starts to appear in pockets.
None of this is dramatic at first. That’s why teams underestimate it.
Cleaning solves the visible invalids (learn how to clean email lists in a detailed manner in its dedicate guide). It does not fix suppression timing errors, retry misconfiguration, or systemic data quality leaks. Email bounce management, when done properly, addresses the entire lifecycle – from how addresses enter your system to how failures are processed and monitored over time.
That’s the difference between maintenance and governance.
The Operational Risk of Ignoring Bounce Governance
Ignoring bounce governance rarely causes instant catastrophe. It causes erosion.
ISPs evaluate consistency. They monitor bounce ratios across campaigns, time periods, and IP pools. If your system repeatedly retries invalid recipients or fails to suppress quickly enough, trust signals degrade quietly. You may see more temporary deferrals. You may notice inconsistent inbox placement. Over time, your sender reputation weakens.
We’ve discussed elsewhere what happens when the bounce rate is high. The operational risk is not just the percentage itself – it’s what that percentage signals about your infrastructure.
Without defined suppression logic, retry policies, and bounce monitoring, your system relies on manual cleanup. Manual cleanup does not scale. And when volume increases, small inefficiencies multiply quickly.
Email bounce management, at its core, is about control.
Control over how your system reacts.
Control over how ISPs interpret your sending behavior.
Control over long-term deliverability stability.
When mature teams implement it properly, bounces stop being a recurring fire to put out. They become structured inputs into a governed sending framework.
The 5-Stage Email Bounce Management Framework
Mature teams don’t improvise when bounces happen. They follow a repeatable lifecycle.
At scale, delivery failures are not isolated incidents. They are structured signals moving through your sending infrastructure. The difference between reactive cleanup and real email bounce management is whether those signals pass through a defined bounce handling workflow with clear rules at every stage.
This is the framework we see working consistently across high-volume senders. Five stages. No guesswork. No manual patchwork.
Stage 1 – Bounce Detection (Tracking Every Failure Signal)
You can’t manage what you don’t capture.
The first stage of the email bounce lifecycle is full visibility. That means ingesting every failure signal from your ESP – not just campaign-level summaries, but raw bounce logs, SMTP response codes, and webhook events in real time.
Most platforms surface a “bounced” status. That’s not enough.
You want structured data:
- SMTP status codes (4xx vs 5xx and subcodes)
- ISP-specific rejection messages
- Time-stamped retry attempts
- Sending IP and domain alignment context
Webhooks should feed these signals into your CRM or data warehouse immediately. Campaign dashboards are useful for high-level review, but operational bounce monitoring requires deeper granularity.
When detection is weak, everything downstream breaks. When detection is structured, every failure becomes actionable data instead of noise in a report.
Stage 2 – Bounce Classification (Hard, Soft, and Beyond)
Once captured, each bounce must be classified correctly.
Yes, there’s the standard hard vs soft distinction. But what matters operationally is how classification drives decision-making.
In mature systems, classification goes further:
- Permanent invalid failures
- Temporary mailbox issues
- Block or policy-based rejections
- Reputation-driven deferrals
- Technical misconfigurations
Not all soft failures are equal. A mailbox full signal is different from an ISP-level block tied to engagement signals. Similarly, some 5xx errors reflect invalid addresses, while others reflect content or authentication problems.
If you want to properly manage bounced emails, your classification layer must translate raw SMTP codes into operational categories. That’s where email deliverability governance begins – not at deletion, but at interpretation.
Stage 3 – Action Protocol (Remove, Retry, or Suppress)
Classification without action rules creates inconsistency.
Stage three defines what happens next.
Hard failure? Immediate permanent suppression. No retries. Suppression logic should update globally across your ESP and CRM to prevent future sends.
Temporary failure? Trigger a retry policy. But not indefinitely. Mature teams define retry limits – for example, three attempts over 72 hours. After the threshold, the contact moves into a review or suppression state.
Block bounces or policy rejections? That’s an escalation trigger. You don’t remove the address. You review sending velocity, recent engagement, and authentication alignment.
This is where tagging logic becomes important. Each bounce event should append metadata to the contact record. Over time, this creates a behavioral history that informs future segmentation decisions.
Without a defined action protocol, teams improvise. With one, the bounce workflow runs automatically and consistently – regardless of campaign size.
Stage 4 – Monitoring & Threshold Alerts
Even with strong suppression and retry logic, systems drift without oversight.
Stage four introduces structured bounce monitoring.
Mature teams define internal trigger thresholds. For example, if a campaign crosses a 2% bounce spike relative to recent averages, it generates an automated alert. Not panic – just investigation.
Alerts should compare:
- Current campaign vs trailing 30-day average
- Segment-level bounce deltas
- IP pool–specific anomalies
This is not about obsessing over industry benchmarks. It’s about internal consistency. If one segment suddenly produces double its usual failure rate, your system should flag it automatically.
Bounce monitoring transforms email bounce management from reactive cleanup into controlled infrastructure oversight.
Stage 5 – Audit & Optimization
The final stage separates advanced teams from everyone else.
Detection, classification, action, and monitoring keep the system stable. Audit and optimization make it stronger over time.
We recommend:
- Weekly operational reviews of bounce categories
- Monthly trend audits across segments and acquisition sources
- Root cause analysis for recurring failure clusters
Are certain lead sources producing disproportionate invalids?
Are specific campaigns triggering block-type rejections?
Is retry logic too aggressive for certain ISPs?
This is where bounce data feeds strategic decisions. Acquisition controls improve. Suppression timing tightens. Segmentation rules evolve.
Verification tools can support prevention at the point of entry, but they are just one layer. The maturity layer is review discipline.
When teams treat the email bounce lifecycle as a governed system – not a reporting metric – bounces stop being campaign interruptions. They become structured feedback loops inside a resilient sending framework.
That’s how scalable bounce handling really works.
Hard Bounce Management SOP (Standard Operating Procedure)
If you’re running volume, your hard bounce removal process cannot be discretionary. It must be rule-based.
In structured email bounce management, hard failures are treated as terminal events. Not warnings. Not review items. Terminal.
The SOP is simple in principle but strict in execution: detect → suppress → sync → prevent re-entry.
When teams struggle with deliverability, it’s often because this step is inconsistently applied. One system suppresses. Another doesn’t. A rep manually re-adds a contact. The cycle repeats.
At scale, you don’t remove hard bounce emails from a list casually. You operationalize permanent suppression as infrastructure.
Why Hard Bounces Must Be Immediately Suppressed
A hard bounce is a definitive delivery failure at the recipient level. Once your ESP confirms it, the address should never enter your active sending pool again.
There should be no retry policy attached to hard failures. Retrying wastes sending attempts, distorts bounce monitoring data, and signals poor hygiene to mailbox providers.
The rule we implement for clients is immediate suppression upon classification. The webhook event triggers an automated update in the ESP. The contact status changes to permanently suppressed. No manual review required.
Delay introduces risk. Even a single accidental resend to an invalid address can inflate bounce ratios within a campaign segment. Multiply that across volume, and your bounce workflow becomes inconsistent.
Hard bounces are not diagnostic events. They are action events.
Permanent Suppression vs Temporary Flags
This is where many teams blur lines.
Temporary flags belong to soft failures or ISP-level deferrals. Hard failures require permanent blacklist logic.
Permanent suppression means:
- The address is excluded from all future sends.
- It is blocked at the ESP level.
- It cannot re-enter active segments through automation.
- It requires explicit administrative override to restore.
Temporary flags, on the other hand, expire based on retry policy thresholds.
The mistake we often see is storing hard bounces as “inactive” instead of “suppressed.” Inactive contacts can re-enter workflows through segmentation errors or CRM sync conflicts.
When you manage bounced emails properly, permanent suppression is a locked state – not a soft label.
This distinction protects long-term deliverability.
CRM and ESP Synchronization Best Practices
Suppression logic must extend beyond your ESP.
If a hard bounce is suppressed in your sending platform but remains active in your CRM, it will reappear. Sales reps re-import lists. Marketing automation re-syncs fields. The invalid address leaks back into circulation.
To prevent this, the hard bounce removal process should include bidirectional sync:
- Webhook triggers suppression in ESP.
- ESP pushes bounce status to CRM in real time.
- CRM marks the contact as permanently undeliverable.
- All automation workflows reference this status before send.
Advanced teams centralize suppression data in a master exclusion table inside their data warehouse. Every sending tool references that source of truth.
That’s infrastructure-level control.
Email bounce management isn’t just about deleting bad data. It’s about ensuring your systems never attempt to send to it again – no matter where it reappears.
When your suppression architecture is airtight, hard bounces stop being recurring problems. They become closed loops inside a governed bounce workflow.
Soft Bounce Retry and Escalation Policy
Hard failures are decisive. Soft failures require judgment.
This is where many teams get sloppy. They either retry indefinitely or suppress too quickly. Neither approach reflects mature email bounce management.
A structured soft bounce retry policy acknowledges that temporary email bounce handling is contextual. Mailbox full errors behave differently from temporary domain outages. ISP deferrals tied to traffic spikes are different from repeated 4xx mailbox errors.
Mature teams define retry windows, escalation triggers, and suppression thresholds in advance. The goal isn’t just to manage bounced emails. It’s to ensure retry behavior aligns with long-term deliverability governance.
When a Soft Bounce Deserves a Retry
Not every soft bounce is equal.
A mailbox full signal often resolves within days. A temporary DNS issue at the receiving domain may clear within hours. Even ISP-side rate limiting can correct itself once traffic normalizes.
In these cases, retrying is appropriate – but controlled.
A well-designed bounce workflow uses time-based retries rather than immediate resend attempts. For example:
- First retry after several hours.
- Second retry within 24–48 hours.
- Stop if the signal persists.
The key is spacing. Aggressive retry attempts can amplify deferrals and distort bounce monitoring metrics.
We’ve seen teams configure retries every 15 minutes. That’s not policy. That’s automation without strategy.
Soft bounce retry logic should reflect recipient-side recovery windows, not sender impatience.
Setting a Retry Limit (And When to Stop)
This is where discipline matters.
A practical soft bounce retry policy typically allows 2–3 attempts over a defined window. After that, the system must escalate.
If an address soft-bounces across multiple campaigns or repeatedly within a short timeframe, the failure is no longer temporary in operational terms.
Your system should track cumulative soft bounce frequency per contact. Once a predefined threshold is crossed – for example, three consecutive campaigns – the contact transitions to a review or suppression state.
This is not about chasing a specific percentage benchmark (we’ve discussed acceptable bounce rate ranges in a separate blog post). Here, the focus is internal consistency.
If retry behavior inflates bounce rates across campaigns, your policy is too permissive. If you suppress after a single temporary error, it’s too aggressive.
Balance comes from structured limits, not guesswork.
Converting Recurring Soft Bounces into Suppressions
Soft failures that repeat become structural risks.
A temporary mailbox full error that appears for weeks is no longer temporary. A domain that consistently returns 4xx deferrals may reflect engagement or policy signals.
At this stage, suppression logic should take over.
Mature teams convert recurring soft bounces into permanent suppressions once defined retry and frequency limits are exceeded. The contact record should store bounce history metadata so segmentation logic can exclude high-risk recipients automatically.
This prevents soft failures from becoming chronic background noise inside your reporting.
In advanced email bounce management systems, escalation from retry to suppression is automatic. No manual review. No campaign-by-campaign decisions.
When temporary email bounce handling is governed by structured limits, you preserve deliverability stability without prematurely discarding recoverable contacts.
That’s the nuance.
And at scale, nuance is what keeps infrastructure resilient.
Suppression List Governance at Scale
Suppression is not a list. It’s a control system.
As sending volume grows, suppression list management becomes one of the most critical components of email bounce management. Not because suppression is complex – but because fragmentation is.
Most organizations don’t operate on a single ESP. They have marketing automation in one platform, transactional email in another, maybe sales outreach in a third. If suppression logic isn’t centralized, you don’t truly manage bounced emails. You just reduce them in isolated pockets.
Governance means every tool respects the same exclusion rules. No exceptions. No blind spots.
When suppression becomes infrastructure rather than a campaign setting, bounce stability improves naturally.
Centralized Suppression Across Multiple ESPs
At scale, suppression must live in a single source of truth.
We’ve seen companies suppress an address in their marketing ESP, only to continue sending transactional emails from a separate system. From the mailbox provider’s perspective, that inconsistency reflects poor sender control.
Best practice is to centralize suppression logic in one of three ways:
- A master suppression database in your CRM or data warehouse
- Real-time webhook synchronization across ESPs
- API-driven suppression propagation across tools
When a bounce event triggers permanent suppression in one system, it must replicate everywhere. That includes marketing automation, product messaging, and any outbound sales platforms.
Multi-ESP environments demand synchronization discipline. Without it, your bounce workflow becomes fragmented.
Suppression list management isn’t about removing contacts. It’s about ensuring every sending node in your ecosystem respects the same deliverability governance framework.
Permanent vs Temporary Suppression Rules
Not all suppressions are equal.
Permanent suppression applies to hard failures, legal opt-outs, and repeated escalation triggers. Once flagged, those addresses should never re-enter active sending unless there’s a deliberate administrative override.
Temporary suppression belongs to structured retry policies and cooling-off periods. For example:
- Short-term ISP throttling
- Temporary domain instability
- Engagement-based cooling windows
The key difference is state durability.
Permanent suppression must be locked and enforced globally. Temporary suppression must expire based on clear logic, not manual guesswork.
Where teams go wrong is storing both under the same generic “inactive” field. That creates ambiguity. Ambiguity leads to accidental reactivation.
Clear state separation strengthens email suppression list best practices and prevents bounce recurrence through structured suppression logic.
Common Suppression Mistakes That Increase Bounce Risk
Most bounce-related suppression failures are operational, not technical.
We repeatedly see three issues:
1. Re-adding Suppressed Contacts: Sales imports old CSV files. A marketing team merges historical lists. An automation workflow repopulates a segment. If suppressed contacts are not excluded at the database level, they quietly return.
2. Poor List Merging Logic: When multiple lists are combined, suppression flags sometimes get overwritten or ignored. Especially in CRM migrations, suppression fields are lost during mapping.
3. Segment Drift: Over time, segmentation rules evolve. If suppression filters aren’t embedded at the base query layer, they depend on campaign-level exclusion – which increases human error risk.
Each of these mistakes weakens suppression governance and allows invalid or risky addresses to re-enter circulation.
Mature email bounce management treats suppression as a non-negotiable system rule. Every campaign references a global exclusion layer. Every data import runs through suppression validation. Every automation checks status before send.
Verification tools and preventive hygiene reduce the number of addresses that need suppression. But governance ensures that once an address qualifies for exclusion, it stays excluded.
That’s the difference between cleanup and infrastructure.
Designing Bounce Automation Workflows Inside Your ESP
Manual review does not scale.
If your team is still exporting CSV files to manage bounced emails, you don’t have a system. You have a reaction loop. Modern email bounce management requires automation at the event level – not after the campaign ends.
A mature bounce automation process turns every failure signal into an immediate system action. Webhooks trigger. Tags update. Suppression logic executes. Alerts fire if thresholds shift.
This isn’t optional for high-volume senders. It’s a marketing ops requirement.
When email bounce workflow automation is configured properly, your team doesn’t “handle” bounces. Your infrastructure does.
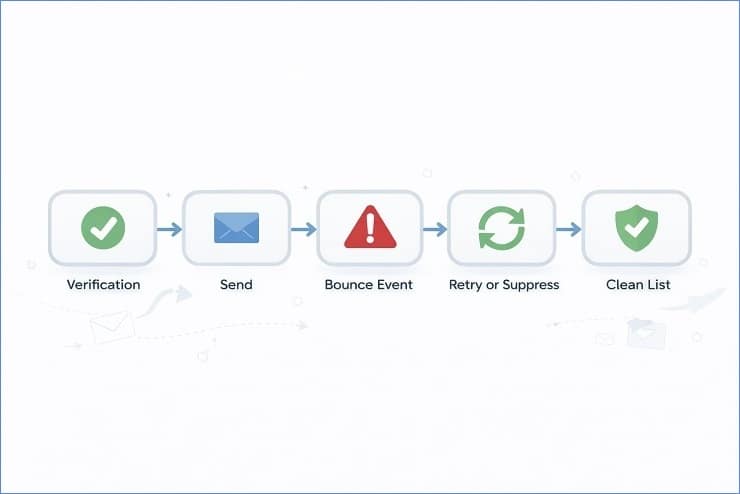
Using Webhooks and Event Triggers
Everything starts with real-time events.
Your ESP should push bounce data through webhooks the moment the SMTP response is received. Not hours later. Not in a daily summary. Immediately.
Each webhook payload should include:
- SMTP status code
- Bounce category
- Campaign ID
- Timestamp
- Sending IP/domain context
That event should trigger downstream automation inside your CRM or data warehouse.
For example:
- Hard failure → update suppression field instantly.
- Soft failure → increment bounce counter on contact record.
- Block or policy bounce → tag for deliverability review.
Without webhook-driven automation, your bounce workflow depends on periodic report checks. That introduces delay. Delay weakens governance.
In high-volume environments, real-time event ingestion is foundational.
Automatic Tagging and Removal Logic
Once the event is captured, action rules must be deterministic.
Automatic tagging is critical. Each contact should accumulate structured metadata:
- hard_bounce_flag = true
- soft_bounce_count = 2
- last_bounce_date = timestamp
- bounce_category = mailbox_full
This tagging feeds suppression logic and segmentation filters. It also supports audit reviews later.
API-based removal should follow predefined rules. If a contact meets suppression criteria, your system should update:
- ESP suppression status
- CRM lifecycle stage
- Master exclusion table
No manual intervention.

This is how you manage bounced emails without introducing inconsistency. Automation eliminates subjective decisions at the campaign level.
And importantly, retry policy logic must be coded. Soft bounces should automatically queue for retry within defined intervals. Once limits are reached, escalation to suppression should occur programmatically.
Automation isn’t about convenience. It’s about precision.
Setting Bounce Rate Spike Alerts
Automation isn’t complete without monitoring triggers.
Your system should track bounce ratios across campaigns and segments in real time. For example, if a campaign historically averages 0.8% and suddenly reports 3.4%, that’s not a cleanup task. That’s a signal.
Threshold triggers can be configured to:
- Send alerts to marketing ops
- Email deliverability stakeholders
- Flag the campaign inside your dashboard
- Pause automation sequences if thresholds are exceeded
The key is relative movement, not just absolute numbers. A spike from 0.8% to 3.4% represents a structural deviation, even if overall rates are still manageable.
Automated bounce monitoring keeps oversight proactive instead of reactive.
When webhooks, tagging logic, API-based suppression, and spike alerts operate together, email bounce management becomes embedded infrastructure. You’re not waiting for damage to appear in reports. Your system responds in real time.
That’s what operational sophistication looks like inside a modern ESP stack.
Bounce Monitoring, Reporting, and Audit Cadence
Automation handles immediate actions. Governance requires review.
Even with a strong email bounce tracking system in place, mature teams don’t rely solely on real-time triggers. They layer structured review cycles on top of their automation. That’s what turns bounce rate monitoring into a control mechanism rather than a dashboard metric.
In scalable email bounce management, monitoring is not reactive. It’s scheduled, comparative, and diagnostic.
We’ve handled accounts sending millions per month. The difference between stable senders and inconsistent ones is rarely technology. It’s cadence. The teams that review bounce patterns methodically catch structural drift early and adjust before it compounds.
Weekly Bounce Reviews
A weekly review is the operational baseline.
This isn’t a casual glance at overall bounce rate. It’s a structured check across:
- Total bounce percentage vs prior week
- Hard vs temporary distribution shifts
- Segment-level deviations
- New suppression volume added
The goal is pattern recognition.
If soft bounce volume increases but hard bounce remains stable, that signals something different than a rise in permanent failures. If suppression additions spike after a specific campaign, that deserves inspection.
When you manage bounced emails within a governed framework, weekly reviews validate that your retry policy, suppression logic, and automation rules are functioning as designed.
It’s less about numbers. More about consistency.
Campaign-Level Bounce Analysis
Campaign comparisons often reveal more than aggregate metrics.
A healthy email bounce tracking system should allow you to compare:
- Similar campaigns month over month
- Promotional vs lifecycle emails
- High-engagement vs cold segments
- Different IP pools or sending domains
For example, if your onboarding sequence consistently produces lower bounce rates than your re-engagement campaigns, that’s expected. But if one promotional campaign shows double the historical average for that segment, the anomaly needs explanation.
This is not about panic. It’s about diagnostic discipline.
Campaign-level analysis also helps validate acquisition assumptions. If a newly imported segment drives disproportionate bounces across multiple sends, the issue may sit upstream – not inside your bounce workflow.
Monitoring at this layer strengthens deliverability governance without repeating benchmark discussions covered elsewhere.
Identifying Bounce Source Patterns
The most valuable insights come from source analysis.
Over time, bounce data accumulates enough signal to trace recurring patterns. Mature teams break bounce monitoring down by:
- Acquisition source (paid ads, webinars, partner lists)
- Signup form or entry point
- Geographic region
- Domain clusters (e.g., corporate vs free providers)
If one lead source consistently generates higher invalid rates, that’s a data integrity issue. If a particular domain cluster shows repeated temporary deferrals, that may reflect engagement or pacing dynamics.
Root cause analysis should be part of your monthly audit cycle. Bounce patterns rarely originate randomly. They reflect structural inputs – how data enters your system, how segmentation evolves, and how sending volume shifts.
When monitoring is tied to audit cadence, email bounce management becomes a feedback loop. Automation handles immediate response. Reviews refine system design.
That’s how stable sending environments are built – not by reacting to single spikes, but by continuously evaluating the infrastructure that processes them.
Who Owns Email Bounce Management? (Team-Level Governance)
At small volumes, bounce handling feels like a campaign task.
At scale, it becomes a governance question.
Email bounce management is not owned by one person clicking “suppress.” It sits at the intersection of marketing operations, deliverability strategy, CRM data control, and infrastructure. If ownership isn’t clearly defined, gaps appear. Suppression logic becomes inconsistent. Retry policy drifts. Monitoring becomes reactive.
We’ve seen this repeatedly in growing teams. Campaign managers assume marketing ops is handling it. Ops assumes the ESP automation is sufficient. Engineering only gets involved when something breaks.
Enterprise-level email deliverability management requires explicit ownership layers. Not shared responsibility. Defined responsibility.

Marketing Operations Responsibilities
Marketing operations typically owns the bounce workflow inside the ESP and CRM.
That includes:
- Configuring suppression logic
- Defining retry thresholds
- Maintaining bounce monitoring dashboards
- Auditing automation rules quarterly
- Ensuring campaign-level reporting aligns with governance policy
Marketing ops is also responsible for ensuring that segmentation filters exclude suppressed contacts and that new data imports follow defined validation standards.
When you manage bounced emails at scale, marketing ops becomes the control center. They don’t manually process failures. They ensure the system processes them correctly.
They should also be reviewing suppression growth trends and cross-checking them against acquisition sources. If suppression volume spikes after a specific import, that’s not a deliverability problem. It’s a data governance issue.
Ops owns the workflow integrity.
Deliverability & Technical Escalation Roles
Not every bounce issue is operational. Some are infrastructural.
This is where a deliverability specialist – internal or external – plays a distinct role.
They step in when:
- Bounce ratios shift across specific ISPs
- SMTP response patterns indicate policy blocks
- IP reputation signals degrade
- Domain-level failures appear across campaigns
This role evaluates SMTP codes, analyzes ISP feedback, and interprets block signals. They determine whether the issue relates to content, email authentication (SPF, DKIM, DMARC), IP warming, or sending cadence.
Deliverability specialists also evaluate whether sending cadence and email warmup protocols were followed when a new domain or IP was introduced, as skipped or rushed warmup is one of the most common root causes of sustained deliverability problems.
Engineering becomes involved when system-level changes are required. That may include webhook adjustments, data pipeline corrections, or integration fixes between ESP and CRM.
Clear separation matters. Marketing ops governs the process. Deliverability specialists interpret signal. Engineering fixes structural gaps.
Without that clarity, email bounce management turns into cross-functional confusion.
Building an Internal Bounce Escalation Matrix
Mature teams document escalation paths before problems occur.
An internal escalation matrix typically defines:
- Thresholds that trigger review (e.g., deviation from historical campaign averages)
- Who is notified first (marketing ops)
- When deliverability review is required
- When engineering must be looped in
- Maximum response time for each severity level
For example: If bounce monitoring shows a sudden domain-specific failure across multiple campaigns, marketing ops validates segmentation first. If confirmed systemic, deliverability reviews SMTP codes. If infrastructure changes are needed, engineering executes.
This prevents overreaction and underreaction at the same time.
The escalation matrix should live alongside your deliverability governance documentation. It formalizes ownership instead of relying on ad-hoc messages.
When roles are defined clearly, bounce management team roles stop overlapping. The system runs predictably. Everyone knows when to act – and when not to.
That’s how you handle bounce governance in environments where sending volume, acquisition channels, and campaign complexity are constantly evolving.
How Bounce Management Protects Your Sender Reputation
Bounce data is not just a reporting metric. It’s a trust signal.
Every major mailbox provider evaluates bounce rate sender reputation patterns as part of its filtering logic. When those signals drift, filtering decisions change. Not instantly. Not dramatically. But progressively.
This is where structured email bounce management moves from operational hygiene to infrastructure protection. When your suppression logic, retry policy, and bounce monitoring systems operate consistently, you reduce unnecessary negative signals flowing back to ISPs.
You don’t “fix” reputation after it drops. You preserve it through governance.

How ISPs Interpret Bounce Signals
ISPs process SMTP responses at scale. They’re not looking at individual campaigns. They’re modeling sender behavior over time.
Repeated attempts to deliver to invalid or unreachable mailboxes signal one of three things:
- Poor list acquisition controls
- Weak suppression logic
- Aggressive retry behavior
Even temporary failures, if retried incorrectly, can create pattern noise. If your bounce workflow continues sending to addresses that consistently return 5xx responses, the system interprets that as disregard for list hygiene controls.
This is where bounce rate sender reputation modeling becomes cumulative. It’s not about one spike. It’s about repeated signals across campaigns.
ISPs factor this into broader scoring models that influence inbox placement, routing priority, and filtering aggressiveness. We’ll break down those reputation scoring mechanics in detail in our dedicated Sender Reputation guide, but the important point here is this: bounce signals feed the trust algorithm continuously.
The Link Between Repeated Bounces and Trust Decay
Trust rarely collapses overnight. It erodes.
When you fail to manage bounced emails with clear suppression and retry boundaries, the decay happens gradually. A small percentage of avoidable bounces persists. Then it grows. Then it becomes normalized inside your system.
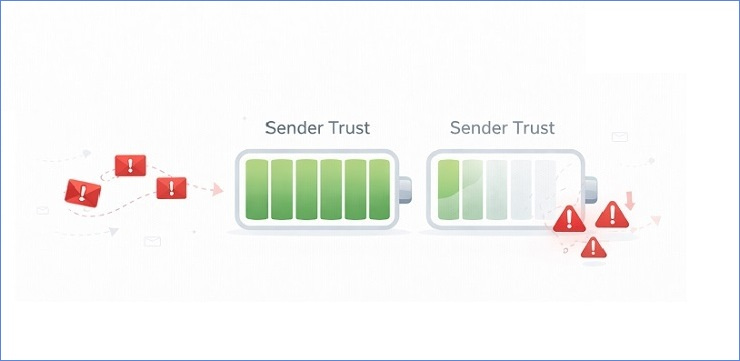
From the ISP perspective, that normalization reflects sender indifference.
Over time, you may see:
- Increased deferrals
- Slower throughput (throttling)
- Higher filtering rates in marginal segments
- Reduced tolerance for engagement dips
None of this requires catastrophic bounce numbers. It requires sustained negative patterns.
Trust decay is subtle. That’s what makes governance important.
Why Governance Reduces Long-Term Deliverability Risk
Well-designed deliverability governance treats bounce data as preventative maintenance.
When suppression logic is enforced consistently, when retry policy limits are codified, and when bounce monitoring flags anomalies early, you eliminate repeat negative signals before they accumulate.
This doesn’t guarantee perfect inbox placement. Nothing does.
But it stabilizes your sender footprint. It reduces volatility. It ensures that infrastructure – not campaign urgency – dictates sending behavior.
Long-term domain health depends on signal consistency. Email bounce management plays a foundational role in that stability.
It’s less about reacting to reputation damage. More about designing systems that prevent gradual erosion in the first place.
Where Email Verification Fits in the Bounce Management Workflow
Verification is preventive. Management is operational.
That distinction matters.
Email verification (through different email verification services) for bounce prevention reduces the volume of invalid addresses entering your system. It filters obvious risk before a campaign goes live. But it does not replace email bounce management. It doesn’t handle retry policy. It doesn’t enforce suppression logic. It doesn’t monitor ISP feedback loops.
We’ve seen teams confuse these layers. They implement verification, see a short-term drop in bounce rate, and assume the system is solved. It isn’t. Verification reduces exposure. Governance controls behavior after exposure.
If you want to prevent email bounces at scale, verification belongs upstream. Management belongs throughout the lifecycle.
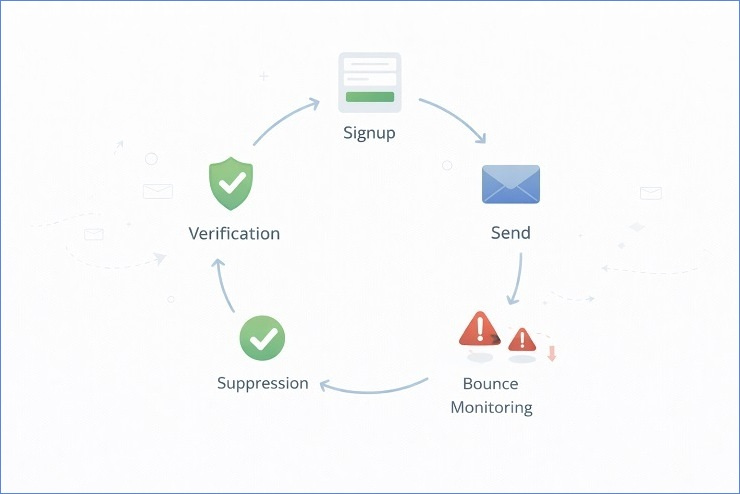
Prevention vs Reaction
Prevention happens before send.
That includes:
- Validating new signups in real time
- Screening imported lists before activation
- Running batch verification before large campaigns
- Blocking known invalid domains at the form level
This reduces unnecessary SMTP failures and protects sender signals early.
But reaction still matters.
Even with high-quality verification, mailboxes become invalid. Employees leave companies. Domains expire. Temporary server conditions shift. Your bounce workflow must capture those events in real time and trigger suppression or retry actions accordingly.
Prevention minimizes risk exposure. Reaction enforces system discipline.
You need both.
Why Verification Alone Isn’t a Management System
Verification checks address validity at a moment in time.
It does not monitor what happens weeks later.
It does not interpret SMTP response trends. It does not detect ISP throttling patterns. It does not escalate domain-level anomalies to your deliverability team.
A mature infrastructure treats verification as one control point inside a broader framework that includes:
- Bounce monitoring dashboards
- Automated suppression updates
- Defined retry thresholds
- Escalation paths when patterns shift
When teams rely solely on verification, they often overlook post-send governance. That’s where silent drift begins.
Email bounce management is continuous. Verification is episodic.
The difference is structural.
Integrating Verification Into Your Lifecycle Framework
The most effective approach is lifecycle integration.
Verification should operate at three key stages:
- Point of capture – Real-time validation at signup or form submission.
- Pre-campaign activation – Batch checks before major sends.
- Reactivation segments – Screening dormant contacts before re-engagement.
After that, your suppression logic and bounce monitoring take over.
A preventive layer like MailCleanup can reduce invalid data entering the funnel. Used correctly, it strengthens upstream data quality. But it works best when embedded inside a defined governance system – not as a standalone fix.
When you manage bounced emails within a structured lifecycle, verification becomes one component of infrastructure. Not the hero. Not the only safeguard.
That’s how you reduce unnecessary bounces without weakening the operational discipline required to sustain deliverability long term.
Conclusion: Email Bounce Management Is Infrastructure, Not Cleanup
At scale, you don’t manage bounced emails with ad-hoc fixes. You design systems that prevent drift.

Strong email bounce management is built on automation, suppression logic, defined retry policy, and consistent bounce monitoring. It’s governed, documented, and reviewed. Not handled reactively after a campaign report raises concerns.
We’ve seen the difference firsthand. Teams that rely on manual cleanup operate in cycles. Teams that treat bounce workflow as infrastructure operate with stability.
Governance replaces guesswork. Automation replaces manual correction. Clear ownership replaces ambiguity.
If you want durable sender performance, build the process – not just the patch.
That’s how modern deliverability governance scales.